AWS GlueとAmazon Athenaの利用を検討している方へ
この記事では、AWS GlueやAmazon Athenaの概要や活用例を知りたい方向けに、それらを使ったデータパイプラインの構築例や運用面について紹介します。
この記事を読むことで、AWS GlueやAmazon Athenaについて把握することができ、実際のデータパイプライン構築やデータ分析の参考にすることができます。
AWS GlueはフルマネージドのETLサービス
AWS GlueはサーバーレスのETLサービスで、データの抽出、変換、ロードを行うことができます。
例えば、Amazon S3・Amazon RDS・Amazon Redshift・Google BigQuery等から取得したデータを用途に応じて変換し、Amazon S3等へ出力することができます。
以下、主要な機能について紹介します。
データカタログでテーブル情報等を管理する
データカタログは、データベース、テーブル、スキーマ情報といったメタデータを保存し、クエリやETLジョブで使用されます。
ちなみに、後ほど紹介するAmazon Athenaは、裏ではAWS Glueのデータカタログ(テーブル情報)を利用してAmazon S3へのクエリを実行します。
ETLジョブでデータ抽出・変換・出力を定義する
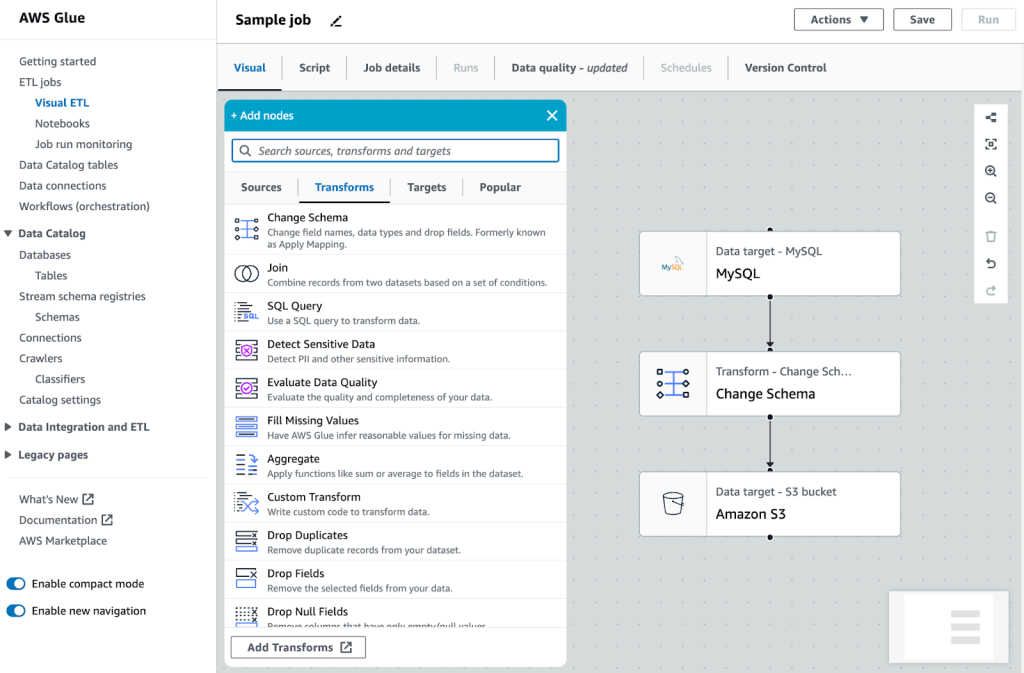
コードを記述することなく、上画像のようにビジュアルでデータ取得元の設定、変換処理、出力先を設定してETLジョブを構築することができます。
実際には、ビジュアルで作成したジョブはPythonまたはScalaのコードが自動生成され、そのスクリプトがジョブの実体となるので、コーディングによるジョブ構築も可能です。
ジョブは容易にスケジューリングすることもできます。
クローラーでデータカタログを更新する
クローラーを設定することで、スケジュール通りにデータストアをスキャンし、データのスキーマを推測してデータカタログを登録・更新することができます。
Amazon AthenaはAmazon S3のデータにSQLクエリを実行できる

Amazon Athenaはサーバーレスのクエリサービスで、Amazon S3に保存されたデータに対して標準的なSQLクエリを実行し、素早く分析できます。
CSV、TSV、JSON、Hadoop 関連形式(ORC、Apache Avro、Parquet)のデータ、Apache WebServer ログ等のデータへのクエリに対応しています。
クエリ結果はAmazon S3へ保存され、BIツールであるAmazon QuickSightでデータの可視化をすることもできます。
SQLクエリを実行してみる
どういったサービスかよくわかるように、Amazon AthenaでSQLクエリを実行してみます。
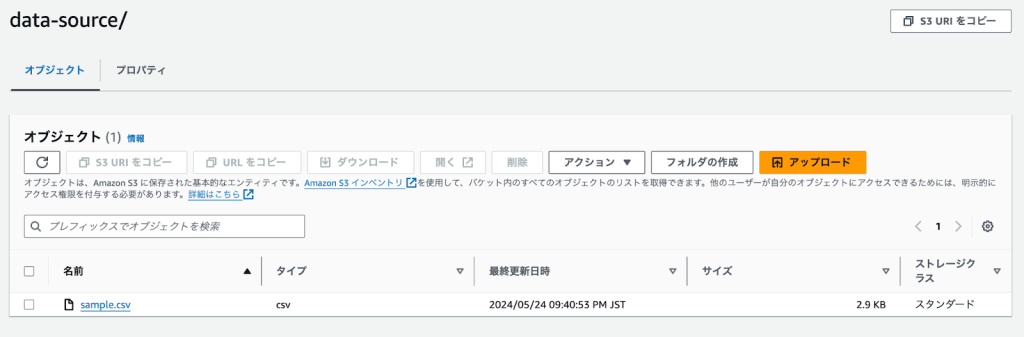
1. データの準備
まず、Amazon S3に以下のようなCSVデータをアップロードしておきます。
timestamp,user_id,page_url,referrer_url,browser,ip_address
2024-05-01 08:00:00,1,/home,/google.com,Chrome,192.168.1.1
2024-05-01 08:01:00,2,/product,/facebook.com,Firefox,192.168.1.2
2024-05-01 08:02:00,3,/contact,/twitter.com,Safari,192.168.1.3
2024-05-01 08:03:00,1,/home,/google.com,Chrome,192.168.1.1
2024-05-01 08:04:00,4,/home,/linkedin.com,Edge,192.168.1.4
2024-05-01 08:05:00,2,/about,/facebook.com,Firefox,192.168.1.2略
2. データカタログの設定
Amazon Athenaでクエリを実行するためには、AWS GlueのデータカタログにAmazon S3データのスキーマ情報を登録しておく必要があります。
これには、AWS Glueのクローラーでスキーマを作成する方法と、手動でテーブルを作成する方法があります。
ここでは簡易化のため、Amazon Athenaで以下のようなSQLクエリを実行してテーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS default.sample (
`timestamp` STRING,
`user_id` STRING,
`page_url` STRING,
`referrer_url` STRING,
`browser` STRING,
`ip_address` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"'
)
LOCATION 's3://sample-bucket-sc/data-source/'
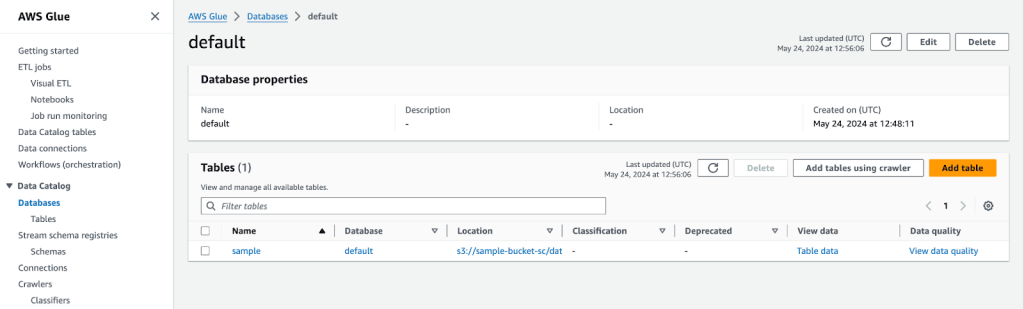
TBLPROPERTIES ('has_encrypted_data'='false');コンソール上でクエリを実行した結果、画像左下に作成されたsampleテーブルが表示されるようになりました。
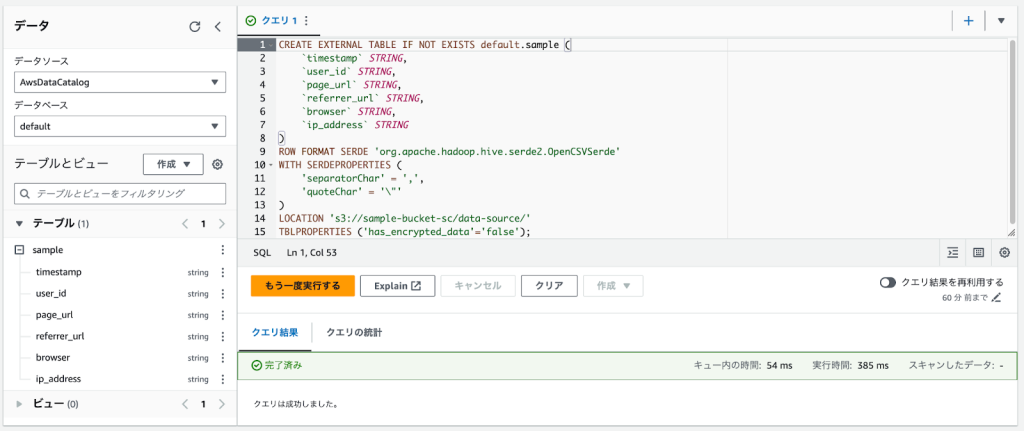
AWS Glueのデータカタログでテーブルが作成されたことも確認できます。
3. SQLクエリの実行
Amazon Athenaコンソール上で適当なSQLクエリを入力して実行してみます。
SELECT * FROM sample WHERE user_id = '1';クエリ実行が完了すると、このように結果がコンソールに表示されます。
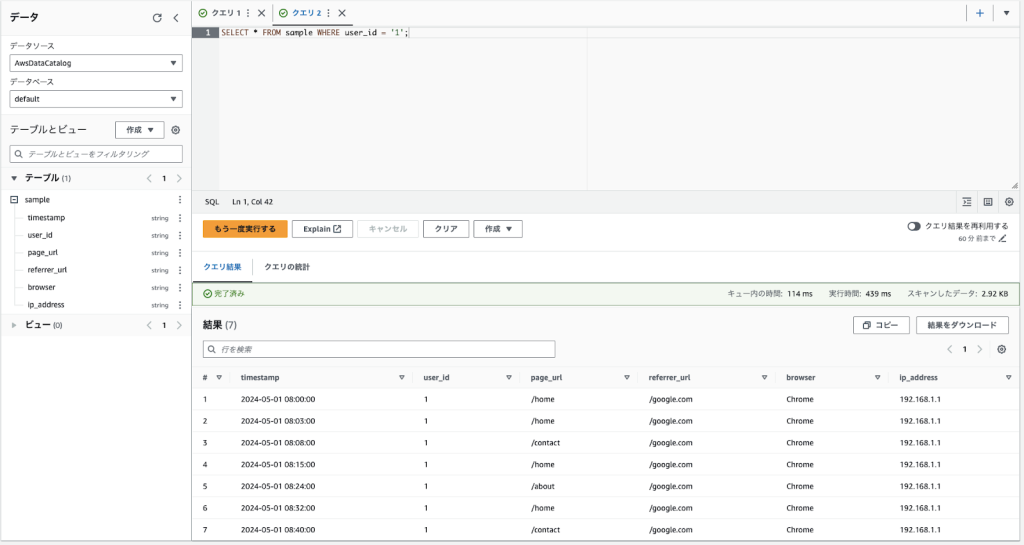
また、クエリ結果は指定されたS3バケットに自動的に保存されます。
このように、Amazon Athenaで容易にSQLクエリを実行できることが確認できたかと思います。
データパイプラインの構築例
ここでは、AWS GlueとAmazon Athenaの利用法を把握できるように、それらを使ったデータパイプラインの構築例を紹介します。
構成図
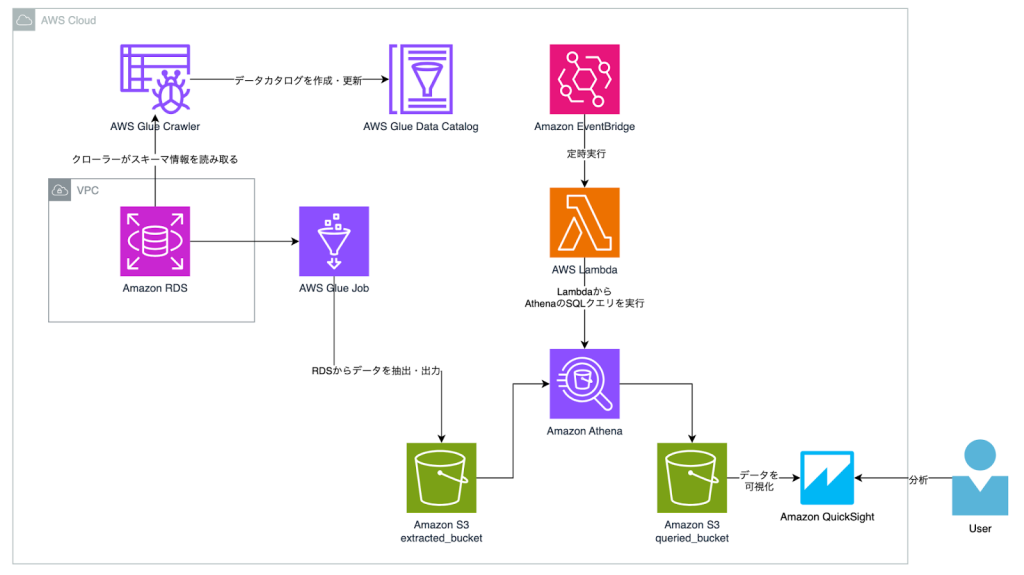
全体の主な流れとしては以下です。
- AWS Glueを利用し、Amazon RDSからデータを抽出してAmazon S3へ出力
- Amazon EventBridgeでスケジュールを組み、AWS LambdaからAmazon AthenaのSQLクエリを定期実行することで目的のデータを抽出
- Amazon QuickSightでデータを可視化して分析
AWS Glueクローラーによるデータカタログ作成・更新
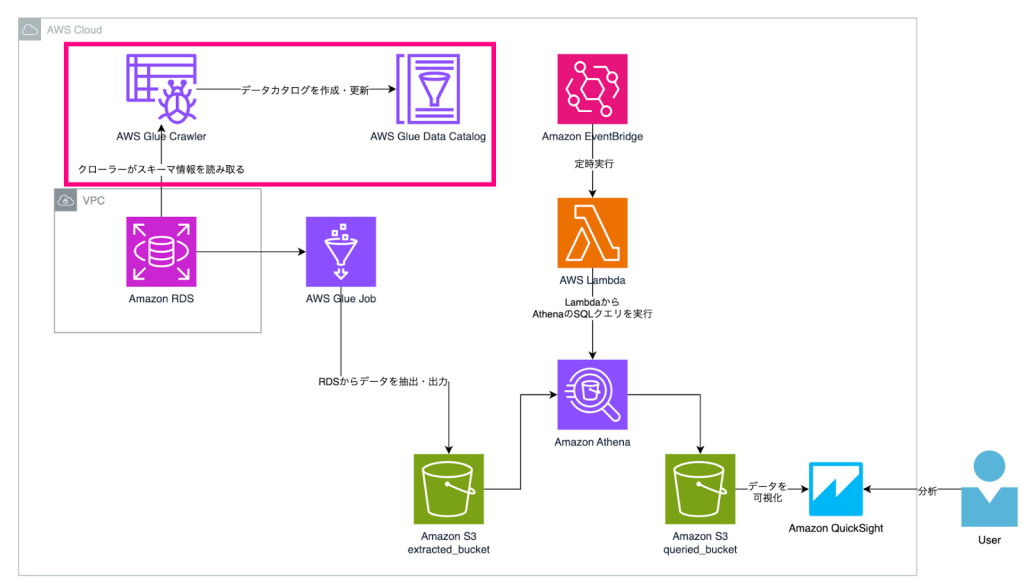
クローラーを設定することで、定期的にデータソースのスキーマ情報を取得してデータカタログを更新できます。
(構成図ではAmazon RDSに対してのみクローラーを実行している形になっていますが、Amazon Athenaクエリ対象のAmazon S3 extracted_bucketに対してクローラーを設定しても良いでしょう)
AWS Glueジョブによるデータ抽出・出力
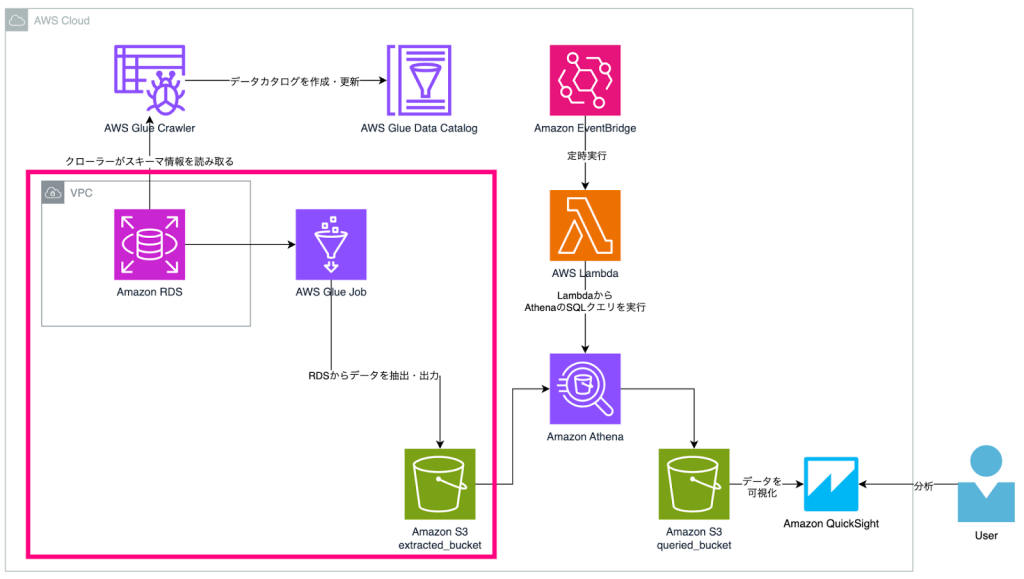
ジョブでデータソースからデータを取得する際、クローラーで取得したデータカタログの情報を用いてデータを取得し、変換・出力を行います。
ここでは例としてデータソースをAmazon RDS、出力先をAmazon S3としましたが他にも多くのサービスに対応しています。
ジョブもスケジュールを組んで定期実行できます。
AWS Lambda + Amazon Athenaによるクエリ・出力
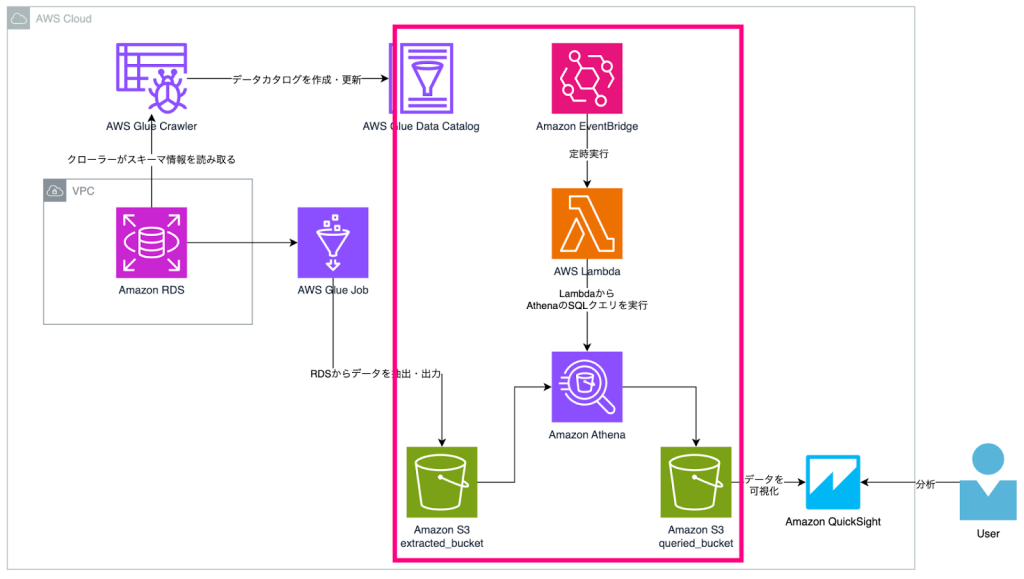
Amazon Athena単体では定期実行させることはできないため、Amazon EventBridgeとAWS Lambdaで定期実行させる形にしています。
Amazon AthenaによるSQLクエリ実行時、パラメーターを受け取って動的にSQLを生成したい場合やより複雑に制御したい場合は、Amazon EventBridgeからAWS Step Functionsを呼び出し、AWS Step Functions内で複数のLambdaを実行させることで要件に対応させることができます。
Amazon QuickSightによるデータ可視化・分析
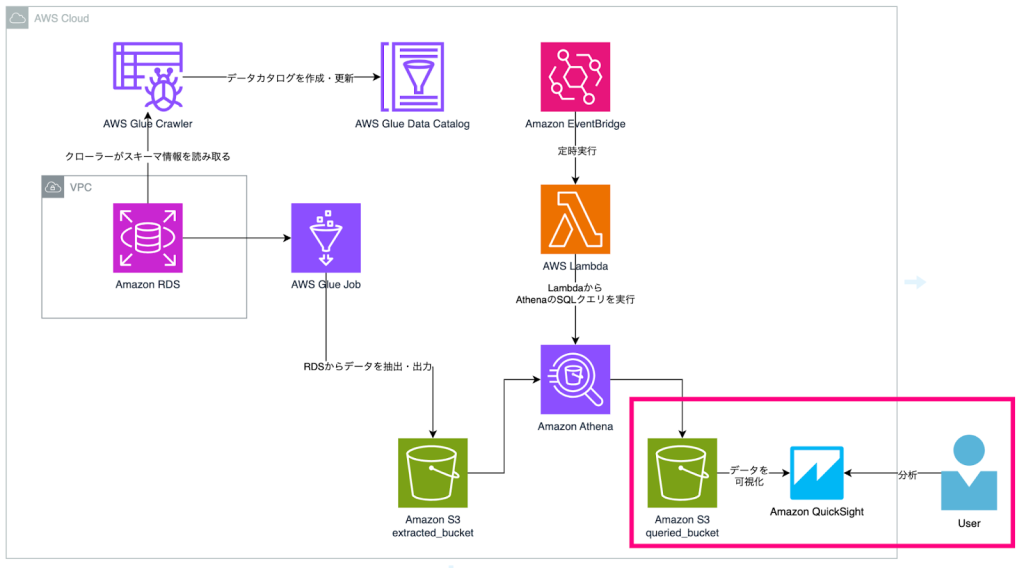
最終的に得られたデータをAmazon QuickSightで可視化することで分析に繋げられます。
データパイプラインの運用例
上記で構築したデータパイプラインの運用面についても補足しておきます。
通知・監視
通知に関しては以下のようなパターンが例として考えられます。
- AWS Glueクローラーの実行結果を通知する
- AWS Glueジョブの実行結果を通知する
- Amazon AthenaによるSQLクエリ実行結果を通知する
上記は、Amazon EventBridgeで実行結果を検出し、Amazon SNSへ連携することでSlack等へ通知をすることができます。
監視に関しては、AWSサービスのみで実現する場合はAmazon CloudWatchで実行失敗等のメトリクスを監視することで障害を検知することができます。
エラー時への対応
エラー時への事前対応としては、以下が考えられます。
- 各実行ログを保管しておく
- 再実行しても問題ないよう、各処理を再実行しても同じ結果になるようにしておく
- 実行失敗時のリトライ設定をしておく
- データ復旧方法を明確にする(Amazon S3のバージョニングをオンにして復元できるようにする等)
再実行はコンソール上から行えるため、「エラー時は再実行すれば良い」という状態にするのも方向性の一つですが、なるべく自動でリトライ・復旧がされれば運用コストをより下げることができます。
コスト最適化
AWS Glue・Amazon Athena・AWS Lambda・Amazon S3等は従量課金です。
主なコスト最適化としては以下が考えられます。
- AWS Glue:計算リソースの最適化
- Amazon Athena:スキャン対象のデータ量を抑える・データ形式を最適化する
- Amazon S3:ライフサイクルポリシーを設定して低料金のストレージクラスへ移行するように設定する
セキュリティ
セキュリティ観点では以下のような対応例があります。
- IAMポリシー最適化:基本的に必要な最小権限になるようにする
- アクセス制限:アクセス制限が必要なデータの場合、S3バケットを別にしてアクセス権限を制限する
まとめ
今回、AWS GlueとAmazon Athenaについて簡単に解説しつつ、それらを使ったデータパイプライン構築の一例をご紹介しました。
本記事で、それぞれのサービスの活用法について理解を深めていただけましたら幸いです。