背景
ChatGPTは現在あらゆるシーンで急速に活用されていますが、企業においてChatGPTを用いたシステムを構築または利用するシーンにおいて特に重視すべきなのはセキュリティも含めたデータ管理です。システムのパフォーマンスを高めながら行うデータの管理について気を付けるポイントを記述します。
1. ChatGPTを用いたシステム構築の概要
1. Azure上でChatGPTシステムを構築するメリット
ChatGPTを利用したシステムを構築する方法は大きく分けて2種類あります。1つはOpen AI のAPIを直接使う方法、もう一方はAzure Open AI serviceを使う方法です。
前者のメリットは最新版のGPTを使用できる点ですが、デメリットはやはりセキュリティとプライバシーです。ユーザーの質問・返答履歴やChatGPTの応答履歴などがOpen AI内で再利用されモデルの再学習に使われる可能性があり、別のユーザーの返答内容に反映される場合もあります。そのような理由で、社内文書情報など秘匿性が高い情報を用いる際には適していません。
一方Azure Open AI serviceであれば、Azure上でセキュアにデータを保存でき、かつGPTに読み込まれたデータも再利用はされません。そのような特性から本記事においては、Azure上においてChatGPTシステムを構築することを想定して記述しています。(図1参照)
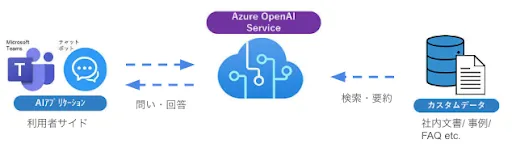
図1:Azure Open AI serviceのシステム概要
2. ChatGPTシステムを学習させる仕組み
Azure Open AI serviceを使ってChatGPTのモデルを学習する仕組みは大きく分けて2つあります。1つ目はプロンプトエンジニアリングです。これはユーザーから受け取った文字列を特定のルールに従って変換する際には有用な方法です。ただ、大量の社内文書を背景とした質問に答えるシステムの学習にはプロンプトエンジニアリングだけでは非常に困難です。
そこで2つ目のファインチューニングを用います。これはGPTモデル自体を変更しようとするもので再学習が伴います。そのため少々複雑ですが、大量のデータが用意できればこれを踏まえた返答を行うモデルの構築が可能になります。(図2参照)
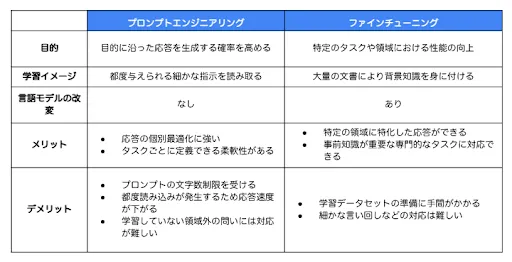
図2:プロンプトエンジニアリングとファインチューニングの比較表
以下、特にデータ管理に関して重要なポイントを記述します。
2. データの管理について気を付けるポイント
1. データの質と整合性
第一に、学習に使用するデータはシステムに求められる要求事項に整合的である必要があります。当然ながら、利用シーンに無関係なデータやユーザーの要求の解釈に誤解を与えるようなデータが多く含まれるとシステムのパフォーマンスは著しい影響を受ける事になります。そのためまず学習に用いるデータは正確であること、要求事項と整合的であること、関連性があることが強く求められます。そのためにも、関連しそうな文書をそのまま学習データとして用いるのではなく、文書内の該当箇所を抽出したり、誤字脱字のクレンジングを行う等によって学習データの品質を確保することが重要です。
Azureにおいては、データクレンジングはAzure Databricksを用い、データの統合・加工はAzure Data Factoryを用いることで一貫してAzure上でデータの前処理が行えるようになっています(データクレンジングについて)。そのため一旦生データをAzure上に置いておけばそのままセキュアに前処理が行えます。もちろん、Azure以外のデータ分析ツールやPythonで前処理したものをAzure上において学習だけ行うということも可能ですが、データ管理が猥雑になるため一貫してAzure上で処理するメリットは大きいです。
2. データセキュリティ
ChatGPTを用いることで容易にデータを参照したり特定することが出来る一方で、機密情報や個人情報などの秘匿性の高い情報を引き出すこともプロンプト次第で可能になります。ChatGPTを使ったシステムは一般的な暗号化などのデータセキリュティだけでは対処が難しくなります。機密情報を引き出すように命ずるプロンプトに対して堅牢であるには、利用者ごとに引き出すことができる情報の機密レベルを定めたり、プロンプトに文字数制限をかける、あるいは禁止語句をトリガーとしたフィルターをかける等が有効です。また常にモニタリングを実施し、迅速にデータの不適切な流出を検知することも重要です。
またChatGPTは学習データとしてユーザーの入力情報や返答内容を再利用する可能性もあるためその点においてもセキュリティ上の注意が必要です。ただし、Azure Open AI serviceで提供されるChatGPTにおいてはデータの再利用を行わないと明記してあります(Azure Open AIのデータポリシー)。
3. プライバシー保護
ユーザーのデータを扱う際には、プライバシーに関する法律や規制(例:GDPR)に準拠することが不可欠です。ユーザーの同意を得た上でデータを使用し、必要に応じて匿名化や擬似化を行うべきです。
日本においてはEU圏内の顧客および関連するビジネスをする場合は限定的かもしれませんが、企業内の文書にユーザーの個人情報などプライバシーに関する情報が含まれている場合は、GDPRにおいてはユーザーの同意を得たり、匿名化を行なったりする必要があります。日本においても、不必要に個人情報を扱うことに対してはリスクが大きいため、厳重に管理し分析の際には匿名化は必須でしょう。Azure上においても匿名化(マスキング)するAzure Synapse Analyticsというツールがありますが、SQLデータベースを元にしたマスキングであるため文書のマスキングは自然言語処理によるマスキングの方が適します。
また前述のようにAzure上のChatGPTシステムにおいてはAzure Open AIのプライバシーポリシーが適用されます。これは「Microsoftの責任あるAIの基本原則」に基づいています。
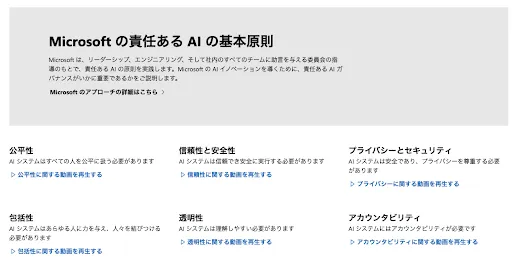
図3: Microsoftの責任あるAIの基本原則
4. データのバイアスと公平性
トレーニングデータに含まれるバイアスがモデルの出力に影響を与える可能性があるため、学習データセットの多様性と代表性を確保し、偏りのない公平なAIモデルを目指すべきです。例えば、ドキュメントの内容に年齢や性別による隔たりがあるために、利用者の属性によってChatGPTシステムの返答内容が変わってくる場合があります。返答内容に客観性を持たせるためにも、学習に用いるデータセットの多様性に注意する必要があります。
5. データストレージとアクセス
大量のデータを効率的に管理するためには、適切なデータストレージの選択と、データへの迅速かつ安全なアクセス方法が重要なのは言うまでもありません。学習用のデータとしてすでにある文書だけでなく、将来に渡って作成する文書あるいはChatGPTシステムの問答データも学習に用いることを考慮すると、データストレージの大きさは可変にすることが望ましいです。例えばAzure Blob Storageであれば、1GBあたり1月0.15ドル程度でストレージを増やすことができます(ストレージの性能(ホット、コールド等)によって金額が変化します)。
6. コンプライアンスの遵守
先ほど触れたGDPRを初めとして、日本においては個人情報保護法を初めとしたコンプライアンスを遵守することはもちろん、問題が発生した際の対策やガイドラインを作成することが重要です。データ管理に関するコンプライアンス遵守のためのベストプラクティスも参考になります。
7. データの更新と維持
AIモデルは時間とともに陳腐化する可能性があるため、定期的にデータを更新し、最新の情報に基づいてモデルを再学習することが重要です。 古くなり業務と関連がなくなった文書や陳腐化した情報はシステムの誤った返答に繋がりパフォーマンスの低下に繋がります。そのため、定期的に学習に用いるデータを見直し、誤解の元となる不要なデータは学習に用いないことが必要になります。
8. パフォーマンスモニタリングと最適化
モデルのパフォーマンスを定期的にモニタリングし、必要に応じてデータの最適化やモデルの調整を行うことが必要です。 データの陳腐化や利用者の要望の変化、多様性の増加などでシステムが当初のパフォーマンスを発揮できなくなることもあります。その際の対策も重要ですが、まずこのような事象を検知することが非常に重要です。そのためには日頃から定期的にシステムのレビューを行いパフォーマンスが想定の範囲内かどうかをモニタリングする必要があります。迅速に検知しパフォーマンス低下の影響を抑えるためには常日頃からのユーザーのフィードバックが重要になってきます。フィードバックを収集する仕組みも忘れずに構築することが重要です。
9. エラー処理と例外管理
不正確あるいは予期せぬプロンプトに対する適切なエラー処理と例外管理を実装することで、システムの堅牢性を保つことが重要です。 特にコンプライアンスに反する質問や回答の可能性がある場合や、誤解を生むような繊細な回答が求められる場合、あるいは学習データセットに該当の項目がない場合は例外的な処理を設けることが望ましいです。これによりシステムの堅牢性や信頼性が向上するため更なる利用の促進に繋がります。また問題が生じる頻度が低下することで業務の滞りを防ぐことにも繋がります。
まとめ
主にAzure Open AI service を使うことを前提に、ChatGPTを用いた企業内質疑応答システムを構築する際のデータ管理について気を付けるポイントを記述しました。
企業内データを用いたモデルのファインチューニングを実施するためにはシステム要件に即した文書データの整理が不可欠になります。これによりデータの正確性や整合性を確保し、さらにセキュリティやプライバシーの要件を満たすように機密情報レベルに沿ったデータの分類やマスキングも重要になります。
特に注意したいのがデータの陳腐化によりモデル自体のパフォーマンスが低下する場合があるということです。日頃からモニタリングを実施し、都度学習データセットの見直しを含めた更新が必要になってきます。
以上のポイントに気を付けることによって、システムのパフォーマンスを維持しつつデータを厳重に管理していくことができます。ご参考になれば幸いです。