目次
- 背景
- アーキテクチャ
- 実装手順
- 事前準備
- インフラ:Terraform
- ダミーデータ生成:Dataproc+Spark
- Rawデータ処理:Dataproc+Spark
- 機械学習モデル構築:VertexAI+Docker
- パイプライン構築:Composer+Python+Slack
- まとめ&自己紹介
背景
今回はWebのログデータの前処理&クリーニングから、データウェアハウスにデータを蓄積し、機械学習に活用までの一連流れをGoogleCloud(以下、GCPと呼ぶ)上で実現したいと思います。不定期的にGoogleCloudStorage(以下、GCSと呼ぶ)にアップロードされているRawデータに対して、GCP上のComposer(ApacheAirflow)でパイプラインを構築して毎日0時から下記の処理を実行します。
- 先ずはある程度の整形&重複排除後データウェアハウスとしてのBigqueryにアウトプットします。
- その後自動的にvertexAIにトレーニングジョブを投げて、機械学習モデルの学習を行い、更新されたモデルをGCSバケットに保存します。
- 各段階の結果をslackに通知を投稿します。
要件として、GCSバケット上でのWebログデータの保存期間が半年です。 クラウド上のインフラ部分ではTerraformで管理し、プログラミング言語についてはデータ処理の部分はScala、パイプライン(DAG)および機械学習の部分はPythonです。
アーキテクチャ

Terraform
Terraformの詳しい紹介については割愛させていただきます。簡単的言うとIac(Infrastructure as Code)ツールで、クラウド上のインフラをコードにより構成することで、terraform applyおよびterraform destroyコマンドで簡単にインフラリソースの作成・削除できます。GCPのCloudShellではTerraformが入っている状態なので、そのままインストールしなくても利用できると思います。
パイプライン構築&制御:CloudComposer
Composer(ApacheAirflow)のメリットとしては、数多くのoperatorがあり、定時実行などの制御も便利し、かつPythonでDAG(有向非巡回グラフ/Directed Acyclic Graph)を作成できます。
生データのクリーニング:Dataproc
分散処理フレームワークSparkとの相性がよいです。Scalaの方に慣れていて、かつ今回はバッチ処理なのでDataflowではなくDataprocを選びました。
データウェアハウス:Bigquery
元々データウェアハウスとして利用されています。
モデルトレーニング:VertexAI
機械学習のシーンとしては、データサイエンティストまたは機械学習エンジニアが作成したpythonファイルをdockerにしてリポジトリに格納してくれます。パイプラインは最新のdocker imageを引っ張られてトレーニングだけを行い、学習済みのモデルをGCSバケットに保存します。dockerの中身に対しては関心を持っていなく、トレーニングジョブだけを実行しよう時は、vertexAIのトレーニングAPIを使用するのは便利だと思います。
通知:Slack
利用中のメインオンラインチャットツールです。
実装手順
事前準備
- GCPのプロジェクトが作成済み
- 各APIが有効になっている(概ね下記のAPIが利用予定です)
- Cloud Logging API
- Compute Engine API
- Cloud Monitoring API
- IAM Service Account Credentials API
- Cloud Composer API
- Cloud Dataproc API
- Cloud Build API
- Artifact Registry API
- Cloud Pub/Sub API
- 権限周りの設定が整っている
- 今回は開発環境なので、サービスアカウントとしてのCompute Engine default service accountにプロジェクトの編集者権限を付けると多分大丈夫だと思いますが、生産環境では厳密な権限管理したほうがいいですね。特に注意点としてComposerV2の立ち上げに対してサービスアカウントに手動で権限付与が必要となります。参考:ステップ 3. Cloud Composer サービス アカウントに必要な権限を付与する
- 言語の開発環境
- 言語のインストールなど開発環境の備えについては割愛させていただきます。バージョンは下記のGitHubまでご覧いただけると幸いです。
インフラ:Terraform
CloudShellのエディタを開き、フォルダ構成を下記のように設定します。

他のリソースを作成する前に、先に必要なGCSバケットを作成します。
下記のコマンドを実行してエラーがあるかどうかを確認
cd ~/Terraform/gcs_bucket/
terraform init
terraform planエラーが表示されないであれば下記のコマンドで構築開始します。 ※バケットの名前はご変更ください。
terraform apply上記にあるバケットが作成され、GCSの画面では確認できます。

DataprocClusterとBigquery連携するためにはbigquery connectorが必要なので、下記のshellscriptを上記作成したバケットにコピーします。
gsutil cp gs://goog-dataproc-initialization-actions-us-east1/connectors/connectors.sh gs://sinkcapital-spark-dependencies-us-east1/参考:GoogleCloudDataproc/spark-bigquery-connector
また、ダミーデータ格納用のフォルダ weblog をバケット user-log-data-us-east1 に作成します。

ここまでGCS方の準備が出来ました。続いて他のリソースも構築していこうと思います。 .tfファイルの内容は下記のように記載されています。
- Bigquery
- リポジトリ、クラスターおよびComposer環境
※Dataprocクラスター作成時の注意点として、イメージのバージョンによりBigqueryとの連携がエラーが発生するかもしれませんので、今回ではバージョンを指定しました。

各モジュールのものを作成します。 ./main.tf
cd ~/Terraform/
terraform plan
terraform apply同じく上記のコマンドを実行し、必要なサービスを構成しました。 すべてのリソースを作成完了するまで少々時間がかかります。

useragent_os_infoのデータが手動でCSVファイルを作成しまして、Bigqueryにアップロードします。 useragent_os_info.csv



ダミーデータ生成:Dataproc+Spark
本物のデータを使うのはNGのため、先にダミーデータを作成します。 毎日0時まで約24時間分、5500万行のデータがGCSバケットに格納されています。
- データフォマード:.json.gz
- データスキーマ:(一部抜粋)
- AccessTime: timestamp
- RecordID: String
- RemoteAddr: String
- IpAddrName: String
- UserAgent:String
- Referrer: String
- SearchWord: String
- Page: String
- Other: String(リスト構成:”都道府県(出身地)”,”職業”,”性別”,”生年月日(1993-12-05)”,”flag1″,”flag2″,”flag3″,”その他1″,…)
Sparkで上記スキーマのダミーデータを生成します。
mvn package コマンドにより生成された SNAPSHOT.jar をGCSバケット(自分の場合は gs://sinkcapital-spark-dependencies-us-east1/ )にアップロードし、下記のコマンドをCloudShellに実行し、spark jobをdataprocのclusterにサミットします。
gcloud dataproc jobs submit spark \
--cluster=spark-scala-job \
--class=util.mockData \
--jars=gs://sinkcapital-spark-dependencies-us-east1/spark_site-data-analysis_inGCP-1.0-SNAPSHOT.jar \
--region=us-east1処理を完了後バケットにデータが確認できます。
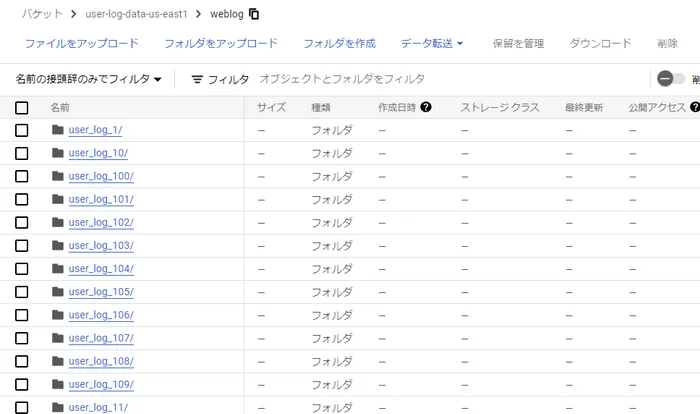

作成されたデータのイメージ:weblog_user_log_1.json.gz
{
"recordID": "ada95948.88db",
"remoteIP": "162.49.220.203",
"userAgent": "Mozilla/5.0 (iPhone12,1; U; CPU iPhone OS 13_0 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Version/10.0 Mobile/15E148 Safari/602.1",
"IpAddress": "Kumamoto",
"referer": "",
"access_time": "2023-02-07 15:14:58",
"page_id": "https://example/?s=nogizaka&paged=21",
"search_word": "",
"other": ",,,2001-11-09,,,,",
}Rawデータ処理:Dataproc+Spark
下記のデータクリーニングを行います:
- AccessTime:StringからTimeStampに変換
- RecordID:削除
- RemoteAddr:保留、group by用のkey、ユーザIDとして使用
- →ユーザでの完全識別はやや無理なので、同じIP+OSで一人のユーザとして認定します。
- IpAddrName:保留
- UserAgent:OS情報だけ抽出、useragent_os_info対照表(Bigquery上にあるマスターテーブル:useragent_os_info)に参照して結合
- Referrer:保留
- SearchWord:保留
- Other:展開、テーブル2として作成
- Page:pageIDだけ抽出
- 重複排除:約5500万行→重複排除後約5000万行残ります
- Bigqueryへの書き込み:テーブル1>>UserInfo、テーブル2>>UserLog
処理用のscala classがこちらになります。sparkETL.scala
Bigqueryからマスターデータを読み込み、ブロードキャスト変数に変換

開発環境の処理のため、フォルダweblogのデータをすべて読み込んで実行する形になっていますが、生産環境ではweblog_yyyymmddのネーミング形式で当日分データを絞ります。
その他についてはコードコメントまでご確認いただければ幸いです。 mvn package コマンドにより先の SNAPSHOT.jar を更新して、GCSバケットに上書きアップロードします。 実際の処理はパイプラインでまとめて実行しようと思います。
機械学習モデル構築:VertexAI+Docker
最近ではあまり機械学習を触っていないので、一番簡単な構成で、prophetの将来予測モデルを作成していきます。 (元々バケットに作成されたモデルが存在済みで、それを更新する形です。)
- モデル:
prophet.py- Bigqueryからデータを読み込むことがありますので、適当な権限が必要です。
- ライブラリ:
requirements.txt(実際にそこまでパッケージが必要ないです。)- VertexAI上にモデルをPoCしてからコンテナ化されるため、その際に必要ないパッケージもつけられています。
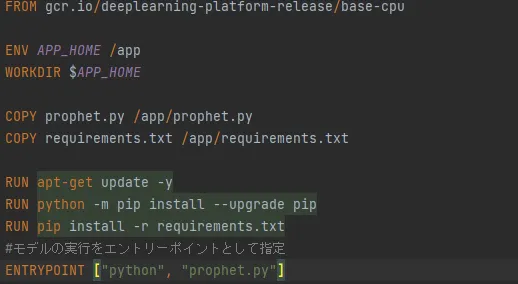
- dockerファイル:
Dockerfile- Googleのオフィシャルイメージを利用して、パッケージをインストール後モデルの実行をエントリーポイントとして指定します。
modelフォルダの下で、Artifact Registryにdockerファイルをpushするコマンドを実行します。

gcloud builds submit --tag us-east1-docker.pkg.dev/sinkcapital-002/model/prophet ./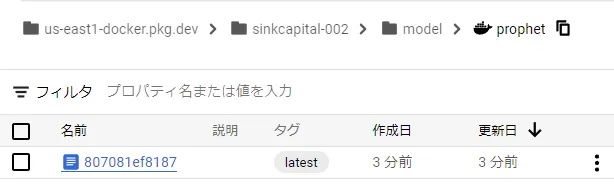
パイプライン構築:Composer+Python+Slack
ComposerのDAGの構成はこちらになります。
dag_base.py:ベースクラス.pyから様々なDAG設定を整えています。dag.pyconfig.json:パラメータはAirflow Variablesから読み込むことにします。
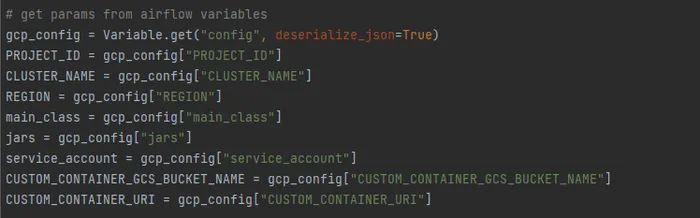
その中、slackへの通知機能では、slackのwebhook_urlを取得しなければならないです。取得の手順についてはgoogle先生まで。取得後AirflowUIでAdmin-ConnectionsにBaseHookを追加します。

DAGファイルをこちらのGCSにあるDAGフォルダにアップロードします。

Airflow上でDAGを確認できます。

開発環境では定時実行を無効に設定していますが、生産環境中では毎日0時で実行します。 右にあるトリガーを押して「Trigger DAG」でDAGを実行してみましょう。途中にもしく権限エラーが出てきたらGCPのIAM画面から権限付与していただければ特に大丈夫と思います。
無事に実行完了後:

Slackに投げた内容:
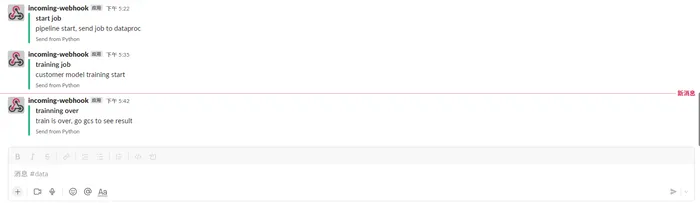
実行結果は各サービスのところで確認できます。
Bigquery: UserInfo

Bigquery: UserLog


GCSバケット上のモデルファイル
まとめ
今回はデータエンジニアの角度から、GCSに格納されたボリュームがある生ログデータに対して、一連処理の流れを紹介・実装させていただきました。 増々バッチ処理ではなくストリーミング処理の方が多くなると感じました。その際に解決策としては、
- 現在のアーキテクチャから、CloudFunctionsを追加して、GCSバケットトリガーしてパイプライン処理を起動する。
- ComposerではなくVertexAIのパイプライン(dataproc->dataflow)を作成する。
などを考えております。 長文になってしまいましたが、最後までお付き合いいただきありがとうございました。
自己紹介
中国出身、名古屋大学大学院経済学研究科産業経営システム卒業、謝暁鋒(シャギョウホウ)と申します。自分はHRT:謙虚(Humility)、尊敬(Respect)、信頼(Trust)という原則を従っております。
- 謙虚:自分が全知全能ではなく、むしろ失敗が多く、常に自分を改善していこう。
- 尊敬:一緒に働く人に対して、1人の人間として扱い、その能力や功績を高く評価しよう。
- 信頼:自分以外の人は有能であり、正しいことをすると信じ、そして仕事を任せよう。
現職ではデータエンジニアとして、主に①全社のデータガバナンス、データウェアハウスのメンテ、②データ蓄積ためのパイプライン構築・作成、③機械学習向け、クラウド上の大規模分析環境構築。前職は AI&データ分析チームのデータサイエンティストとして様々な案件を参加しました。